



Pods
In Kubernetes, a pod is the smallest deployable unit that represents a single instance of a running process in a cluster. A pod encapsulates one or more containers that share the same network namespace and storage volumes. The containers in a pod run together on the same worker node and can communicate with each other using localhost.
Pods provide a way to manage containerized applications in Kubernetes, and they are commonly used to host microservices. Pods can be managed through Kubernetes controllers such as Deployments, ReplicaSets, and StatefulSets, which provide automated scaling, rolling updates, and self-healing capabilities.
Using the YAML configuration shown below, we can create a pod with the Nginx container. And follow
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
type: frontend
spec:
containers:
- name: nginx
image: nginx
kubectl apply -f DemoNginxPod.yaml

Kubectl get pods

Commands that help to play with pods
kubectl get pods -o wide # output with more details
kubectl describe pod nginx # gives description about ngix pod
Replication Controllers and ReplicaSets
ReplicaController is a resource object that ensures that a specified number of replica pods are running at any given time. It is a type of Kubernetes controller that helps to ensure the desired state of a deployment.
A ReplicaController monitors the state of a set of pods and makes sure that a specified number of replicas are always running. If a pod fails or is terminated, the ReplicaController creates a new replica to replace it. If there are too many replicas, the ReplicaController will terminate the excess replicas.
creating ReplicaController
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx2
spec:
replicas: 3
selector:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
containers:
- name: nginx
image: nginx
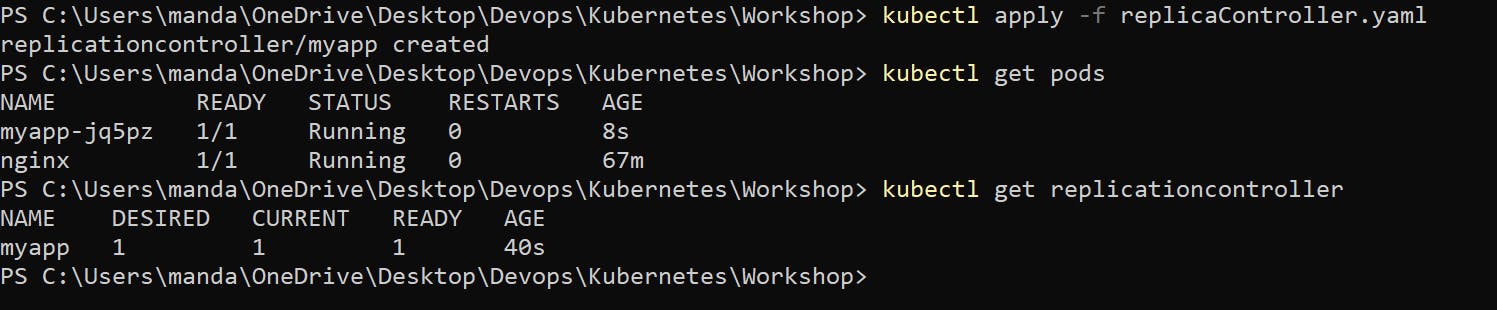
To get the replication controller we have the command
kubectl get replicationController
kubectl get pods # To check the created replicas
Replica Set
In Kubernetes, a replica set is a controller that helps to ensure that a specified number of replica pods are running at any given time. The replica set controller is responsible for creating, scaling, and managing a set of identical pod replicas to ensure high availability and fault tolerance.
In a Kubernetes replica set, the desired number of replicas is specified in the replica set configuration. The replica set controller then monitors the number of replicas running and automatically creates or deletes pod replicas as necessary to maintain the desired number.
Replica sets are often used in conjunction with other Kubernetes objects, such as deployments, which define how pods should be updated and rolled out. Replica sets help to ensure that the desired number of replicas is maintained during deployments and updates, reducing downtime and ensuring that applications remain available to users.
Example:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-replicaset
labels:
app: myapp-replicaset
type: frontend
spec:
selector:
matchLabels:
app: myapp-replicaset
template:
metadata:
name: myapp-replicaset
labels:
app: myapp-replicaset
spec:
containers:
- name: nginx-replica
image: nginx
replicas: 2
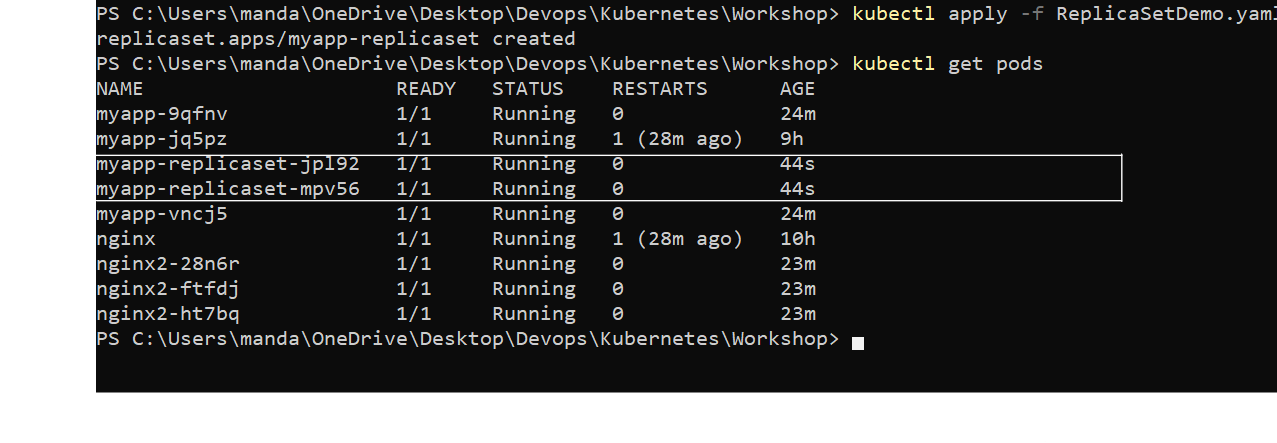
kubectl get replicaset
kubectl delete replicaset myapp-replicaset
kubectl replace -f ReplicaSetDemo.yaml
kubectl scale --replicas=6 -f ReplicaSet.yaml
Labels and Selectors
Labels are key/value pairs that can be attached to Kubernetes resources such as pods, services, and deployments. They are used to identify and categorize resources, making it easy to organize and manage them. For example, you can use labels to group pods that belong to a particular application or service.
Selectors, on the other hand, are used to select resources based on their labels. A selector is a field in a Kubernetes resource that specifies a set of label requirements that must be met by other resources for them to be considered a match. For example, you can use a selector to select all pods that have a specific set of labels.

Deployments
Deployment in Kubernetes is a declarative way to manage a set of replicas of a Pod. It allows you to define the desired state of your application and Kubernetes takes care of making sure that the actual state matches the desired state. As a result of the deployment, we can smoothly upgrade the underlying instances using rolling updates, Android modifications, and pause and resume changes as necessary. to design a deployment. To create a deployment in Kubernetes we can use following YAML configuration.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
spec:
replicas: 2
selector:
matchLabels:
app: myapp-deployment
template:
metadata:
labels:
app: myapp-deployment
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 8080
Commands
kubectl apply -f deployment.yaml
kubectl get deployments
kubectl get replicaset # along with deployment replicaset also created
kubectl get pods
kubectl get all
Rollout and Versioning
When we create a deployment, it triggers a rollout. a new rollout creates a new deployment revision.
Rollout refers to the process of deploying a new version of your application to a Kubernetes cluster. This process involves updating the container image, configuration files, and other resources required by your application. Kubernetes provides several deployment strategies for rolling out new versions of your application, including rolling updates, and blue-green deployment.
Rolling updates are the most common deployment strategy in Kubernetes, which involves gradually updating pods in a deployment one by one while monitoring the health of the application to ensure that it is running smoothly.
Versioning, on the other hand, is the process of assigning unique identifiers (i.e., version numbers) to different releases of your application. In Kubernetes, you can use labels and annotations to version your deployments, pods, and other resources. This helps you keep track of different versions of your application and roll back to previous versions if needed.
kubectl rollout status deployment/myapp-deployment
kubectl rollout history deployment/myapp-deployment
kubectl rollout undo deployment/myapp-deployment
Basics Of Networking in Kubernetes
Let's discuss a single-node Kubernetes cluster. The node has an IP address of (192.100.1.2). This is the IP address we used to access the Kubernetes cluster and SSH into the cluster, etc. For example, a minikube is a single-node cluster where one node acts as a control plane and a worker node.
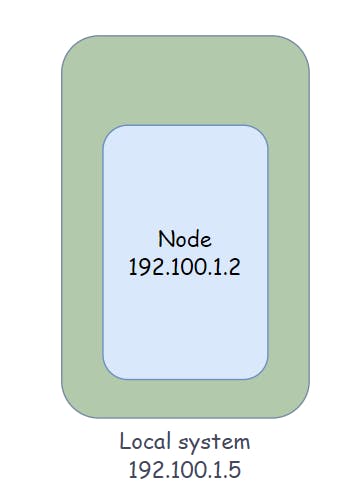
In the Kubernetes world, the IP address is assigned to a pod instead of a container. Kubernetes uses a flat, overlay network that allows for communication between different containers running on different nodes. When two nodes have the same IP address then it causes internal IP conflicts in the network. so the overlay network is created using a networking plugin, which can be either built into Kubernetes or provided by a third-party vendor.
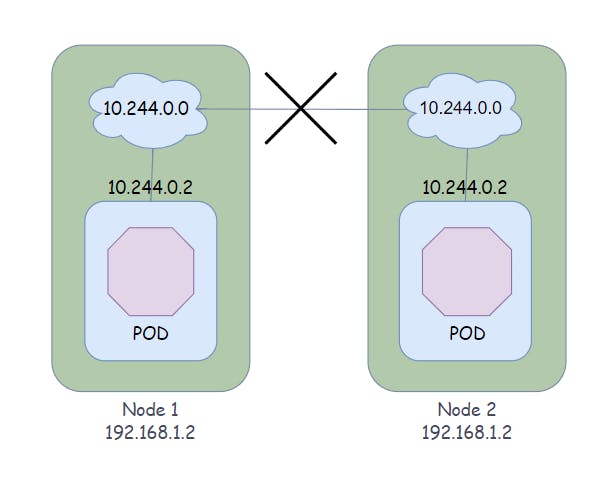
One of the most common networking plugins used with Kubernetes is Flannel. Flannel creates a virtual network that spans across all of the nodes in a Kubernetes cluster. This network allows for communication between different containers, regardless of which node they are running on.
Kubernetes also provides a service abstraction that enables a set of containers to be exposed as a network service. This service abstraction provides load balancing and service discovery, allowing other containers in the cluster to easily discover and communicate with the service.